MICHAEL NOLAN

Social media and advertising-technology company Meta recently released an update to its large language model Llama. Llama 2 was released as open source, providing users access to the model’s weights, evaluation code, and documentation. Meta states the open-source release was intended to make the model “accessible to individuals, creators, researchers, and businesses so they can experiment, innovate, and scale their ideas responsibly.”
However, compared to other open-source LLMs and open-source software packages more generally, Llama 2 is considerably closed off. Though Meta has made the trained model available, it is not sharing the model’s training data or the code used to train it. While thirdparties have been able to create applications that extend on the base model, aspiring developers and researchers have a limited ability to pick apart the model as is.
In research presented at the ACM Conference on Conversational User Interfaces, a group of AI researchers at Radboud University, in Nijmegen, Netherlands, argue that Llama 2 is not the only LLM to be questionably labeled as “open source.” In the paper, the scientists present a multidimensional assessment of model openness. They use this rubric to score 15 different nominally open-source LLMs on different aspects of their availability, documentation, and methods of access. The researchers have collected these assessments in an online table that they have since expanded to include 21 different open-source models. Smaller, research-focused models were included in the assessment if they were deemed, as stated in the preprint, “open, sufficiently documented, and released under an open source license.”
“Meta using the term ‘open source’ for this is positively misleading.” —Mark Dingemanse, Radboud University
The scientists started the project when looking for AI models to use in their own teaching and research. “If you write a research paper, you want the results to be reproducible for as long as possible,” says Andreas Liesenfeld, one of the preprint’s authors and an assistant professor at Radboud. “That’s something you would specifically value if you do research using these technologies, right? That’s something we did not see, for instance, from ChatGPT”—the chat-bot interface built off of OpenAI’s Generative Pretrained Transformer (GPT) LLM series. Despite what may be inferred from its name, OpenAI closed access to much of its research code after launching GPT-4 and receiving a substantial investment from Microsoft earlier this year.
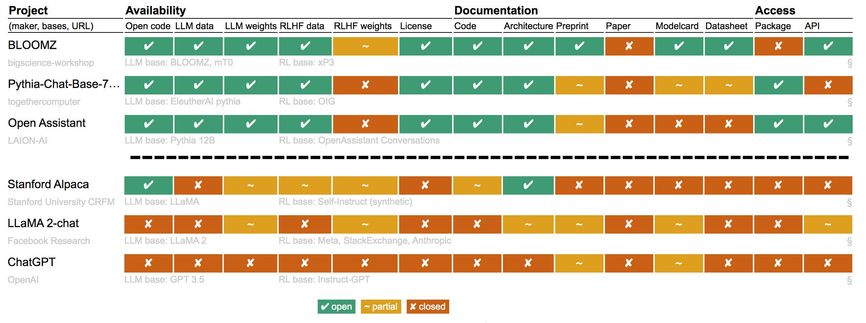 The Radboud University team’s assessment gives very poor marks to ChatGPT’s and Llama’s open-source status. (The full table had 20 entries at press time, we show only the top and bottom entries here.)
The Radboud University team’s assessment gives very poor marks to ChatGPT’s and Llama’s open-source status. (The full table had 20 entries at press time, we show only the top and bottom entries here.)In fact, OpenAI’s ChatGPT model has scored the worst out of all models currently assessed on the team’s openness table. Of the available statuses—open, partial, and closed—ChatGPT is marked “closed” in all assessments other than “model card”—a standard format for describing the model and its limitations—and “preprint”—whether or not there is an in-depth research paper about the model. For these two, ChatGPT only gets a “partial” grade. Llama 2 is ranked second worst overall with an overall openness ranking only marginally better than that of ChatGPT.
AI’s Reproducibility Problems
Liesenfeld’s concerns about the reproducibility of ChatGPT-based research have borne some evidentiary fruit. A separate preprint from scientists at Stanford University and the University of California, Berkeley, recently demonstrated that both GPT-4 and GPT-3.5’s performance on reasoning tasks has changed between March and June of this year, mostly for the worse. These changes have occurred without any accompanying announcement from OpenAI. Such changes may prevent the reproduction of any research results produced from the use of these models during that time period.
While Liesenfeld and their colleagues determined that several smaller, research-focused models were considerably more open than Llama 2 or ChatGPT, they found that all the models they assessed were closed in two key ways. First, very few of the models gave sufficient detail of the important refinement process required of modern LLM function, also known as reinforcement learning with human feedback (RLHF). This key step, which tunes language models to give useful outputs from the statistical patterns trained into them during model pretraining, appears to be the secret sauce behind contemporary LLM performance. The process is labor-intensive, requiring human-in-the-loop assessment of model outputs during training.
The second major issue the researchers point to is the ways commercial LLM releases have avoided the peer review process. While publishing model architecture, training methods, and performance through reviewed conferences or journals is a well-established practice in academic research, ChatGPT and Llama 2 were both released with only a company-hosted preprint document, most likely to protect trade secret details around model structure and training.
While the light this project shines on the variable openness of LLMs may in fact push the field toward truly open-source model development, Liesenfeld and colleagues remain wary of commercial model use in academic research. Mark Dingemanse, a coauthor of this report, had a particularly strong assessment of the Llama 2 model: “Meta using the term ‘open source’ for this is positively misleading: There is no source to be seen, the training data is entirely undocumented, and beyond the glossy charts the technical documentation is really rather poor. We do not know why Meta is so intent on getting everyone into this model, but the history of this company’s choices does not inspire confidence. Users beware.”
This story was corrected on 27 July 2023 to indicate that the Radbound group’s research was presented at a conference in July.
No comments:
Post a Comment